04-1. Multivariable Linear regression
본 글은 '모두를 위한 딥러닝 시즌 2'와 'pytorch로 시작하는 딥 러닝 입문'을 보며 공부한 내용을 정리한 글입니다.
필자의 의견이 섞여 들어가 부정확한 내용이 존재할 수 있습니다.
여러개의 정보에서 하나의 추측값을 얻어내는 직선을 찾는 과정
즉, 이번에는 다수의 x에서 하나의 y를 추출하는 과정이다.
1. Hypothesis Function
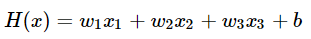
입력 변수가 3개라고 가정했을 때의 식이다. x가 3개라면 w(가중치)도 3개다.
그런데 이렇게 naive하게 나타내가 보면, x의 개수가 매우 많아졌을 땐 죽음 뿐......
그래서 이때, 행렬의 특성을 사용한다.
2. Dot product
일일히 곱하지 않고, x텐서와 w텐서를 한번에 곱해주고 싶어! => 내적을 이용하자.
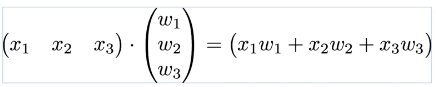
(더 자세한 행렬 연산은 https://wikidocs.net/54841 을 참조하시면 좋습니다)
위와 같이 나타내면, 다음과 같은 식으로 간단하게 나타낼 수 있다! (편향 제외)
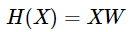
편향을 추가한다면 더해주기만 하면 된다.
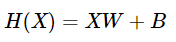
pytorch에서 dot product는 다음과 같이 나타낸다.
H = X.matmul(w)
이때, w는 w = torch.zeros((3, 1), requires_grad = True) 이다. x의 개수가 3개니까 w도 3*1 텐서이다.
3. Full Code
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
#x와 y값을 입력 - 한개의 x에 3개의 요소! 5개는 test set의 개수일 뿐임.
x_train = torch.FloatTensor([[73, 80, 75],
[93, 88, 93],
[89, 91, 90],
[96, 98, 100],
[73, 66, 70]])
y_train = torch.FloatTensor([[152], [185], [180], [196], [142]])
# 모델 초기화
W = torch.zeros((3, 1), requires_grad=True)
#행렬의 곱을 위해 숫자맞춰줘야함.(x의 요쇼?가 3개이니까 W는 3x1이여야 함 => x의 요소에 각각 대응하게)
b = torch.zeros(1, requires_grad=True)
#편향은 하나! dot product가 요소들끼리 곱하고 더하는거기 때문에 결과는 하나만 나오게 되어있음
# optimizer 설정 - sgd를 사용함
optimizer = optim.SGD([W, b], lr=1e-5) #지수계산법, 0.00001임
nb_epochs = 1000
for epoch in range(nb_epochs + 1):
# H(x) 계산 - 가설을 세울 때 dot product사용.
hypothesis = x_train.matmul(W) + b
# cost 계산 - mse사용
cost = torch.mean((hypothesis - y_train) ** 2)
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
# 100번마다 로그 출력
if epoch % 100 ==0:
print('Epoch {:4d}/{} hypothesis: {} Cost: {:.6f}'.format(
epoch, nb_epochs, hypothesis.squeeze().detach(), cost.item()
))4. Full code with nn.Module
이번에는 식까지 직접 코딩하는게 아니라, pytorch에 친절하게 내장되어 있는 함수들을 이용해서 위의 코드들을 바꿔보자!
1) mse를 적용에 있어서, 이번에는 직접 식을 입력하지 않고, pytorch의 torch.nn.function에서 제공하는 mse를 이용해보자.
import torch.nn.function as F
cost = F.mse_loss(prediction, y_train)
#인자로 받은 얘들을 빼서 제곱한 값의 평균을 리턴한다.
2) 선형 회귀 모델의 식을 직접 세워주지 않고, nn.Linear()을 이용해보자.
import torch.nn as nn
model = nn.Linear(input_dim, output_dim)
-1. 단순 선형 회귀
import torch
import torch.nn as nn
import torch.nn.functional as F
torch.manual_seed(1)
# 데이터
x_train = torch.FloatTensor([[1], [2], [3]])
y_train = torch.FloatTensor([[2], [4], [6]])
# 모델을 선언 및 초기화. 단순 선형 회귀이므로 input_dim=1, output_dim=1.
model = nn.Linear(1,1)
# optimizer 설정. 경사 하강법 SGD를 사용하고 learning rate를 의미하는 lr은 0.01
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 전체 훈련 데이터에 대해 경사 하강법을 2,000회 반복
nb_epochs = 2000
for epoch in range(nb_epochs+1):
# H(x) 계산
prediction = model(x_train)
# cost 계산
cost = F.mse_loss(prediction, y_train) # <== 파이토치에서 제공하는 평균 제곱 오차 함수
# cost로 H(x) 개선하는 부분
# gradient를 0으로 초기화
optimizer.zero_grad()
# 비용 함수를 미분하여 gradient 계산
cost.backward() # backward 연산
# W와 b를 업데이트
optimizer.step()
if epoch % 100 == 0:
# 100번마다 로그 출력
print('Epoch {:4d}/{} Cost: {:.6f}'.format(
epoch, nb_epochs, cost.item()
))
-2. 다중 선형 회귀
import torch
import torch.nn as nn
import torch.nn.functional as F
torch.manual_seed(1)
# 데이터
x_train = torch.FloatTensor([[73, 80, 75],
[93, 88, 93],
[89, 91, 90],
[96, 98, 100],
[73, 66, 70]])
y_train = torch.FloatTensor([[152], [185], [180], [196], [142]])
# 모델을 선언 및 초기화. 다중 선형 회귀이므로 input_dim=3, output_dim=1.
model = nn.Linear(3,1)
optimizer = torch.optim.SGD(model.parameters(), lr=1e-5)
nb_epochs = 2000
for epoch in range(nb_epochs+1):
# H(x) 계산
prediction = model(x_train)
# model(x_train)은 model.forward(x_train)와 동일함.
# cost 계산
cost = F.mse_loss(prediction, y_train) # <== 파이토치에서 제공하는 평균 제곱 오차 함수
# cost로 H(x) 개선하는 부분
# gradient를 0으로 초기화
optimizer.zero_grad()
# 비용 함수를 미분하여 gradient 계산
cost.backward()
# W와 b를 업데이트
optimizer.step()
if epoch % 100 == 0:
# 100번마다 로그 출력
print('Epoch {:4d}/{} Cost: {:.6f}'.format(
epoch, nb_epochs, cost.item()
))
+) 순전파, 역전파(forward, backward)
https://excelsior-cjh.tistory.com/171
03. 오차역전파 - BackPropagation
이번 포스팅은 '밑바닥부터 시작하는 딥러닝' 교재로 공부한 것을 정리한 것입니다. 아래의 이미지들은 해당 교재의 GitHub에서 가져왔으며, 혹시 문제가 된다면 이 포스팅은 삭제하도록 하겠습니다.. ㅜㅜ 오차역..
excelsior-cjh.tistory.com
<Reference>
https://deeplearningzerotoall.github.io/season2/lec_pytorch.html