05. Logistic Regression
본 글은 '모두를 위한 딥러닝 시즌 2'와 'pytorch로 시작하는 딥 러닝 입문'을 보며 공부한 내용을 정리한 글입니다.
필자의 의견이 섞여 들어가 부정확한 내용이 존재할 수 있습니다.
로지스틱 회귀 : 이진 분류!
0. binary classification
- 이진 분류, 0 또는 1로 분류하는 형태.
0또는 1로 분류를 할 때는 0으로 쭉 가다가 특정한 점에서 갑자기 1이되고, 이후에 쭉 1이 되는 계단 함수, step function이 제일 이상적이다. 그러나 미분을 할 때 등등 계산에 불편함이 많다. 그래서 계단과 유사한 S자 형태를 표현 할 수 있는 함수가 필요하다. S자 형태를 표현하기 위해서는 특정 함수 f를 추가적으로 사용해서 아래의 형태를 이뤄야 한다.
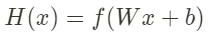
여기서 f 에 적합한 함수가 바로 시그모이드!
1. Sigmoid function
시그모이드 함수의 방적식은 다음과 같다.
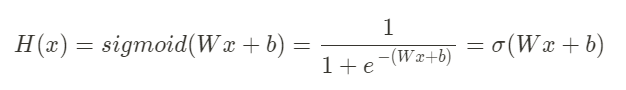
시그모이드 함수는 W의 값이 커지면 경사가 커지고 W의 값이 작아지면 경사가 작아지며, b의 값에 의해 그래프가 좌우로 이동한다. 선형 회귀와 마찬가지로, 여기서도 최적의 W와 b를 찾는 것이 목표가 된다.
또한, 시그모이드를 사용한다면, 임계값을 조절해서 0과 1의 분류가 가능하다. 만약 0.5를 임계값으로 사용한다면, 이를 넘으면 1, 아니면 0으로 처리해서 분류할 수 있다.
2. Cost function
선형 회귀 때 사용했던 것 처럼 MSE를 사용하게 된다면, non-convex형태의 미분값이 나오게 된다. 이런 그래프에는 경사 하강법을 사용하기 부적절해진다. 그럼, convex하게 그래프를 만들려면 어떤 cost function을 사용해야 할까?
시그모이드 함수의 특징은 함수의 출력값이 0과 1사이의 값이라는 점이다. 즉, 실제값이 1일 때 예측값이 0에 가까워지면 오차가 커져야 하며, 실제값이 0일 때, 예측값이 1에 가까워지면 오차가 커져야 한다. 이를 충족하는 함수가 바로 로그 함수다! 두개의 로그함수를 0.5를 대칭으로 겹친다면, 저 조건을 충족하는 cost function을 만들 수 있다. 다음은 y=0.5에 대칭하는 두 개의 로그 함수 그래프이다.
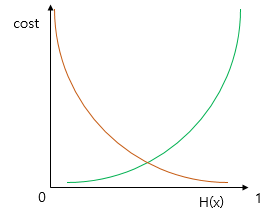
식으로 표현한다면, 아래와 같다.
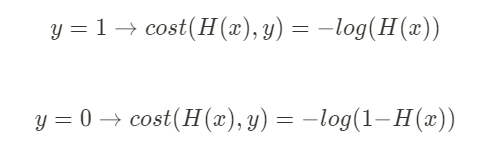
이 두식을 하나로 합칠 수도 있다.
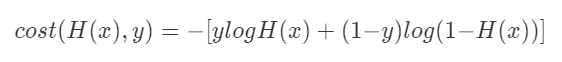
결과적으로 이 식을 사용해서 sigmoid의 "모든 오차의 평균"을 구할 수 있다.
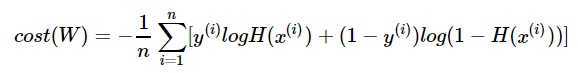
이 비용 함수를 코드로 구현할 때, pytorch를 이용해서 다음와 같이 할 수 있다.
F.binary_cross_entropy(H(x), y)binary cross entropy, BCE 라고도 불리며, 0아니면 1을 리턴한다.
3. Full code
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
x_data = [[1, 2], [2, 3], [3, 1], [4, 3], [5, 3], [6, 2]]
y_data = [[0], [0], [0], [1], [1], [1]] #분류니까 0 아니면 1
x_train = torch.FloatTensor(x_data) # 데이터를 텐서로 바꿔주기
y_train = torch.FloatTensor(y_data)
W = torch.zeros((2, 1), requires_grad=True) # 크기는 2 x 1
b = torch.zeros(1, requires_grad=True)
# hypothesis = 1 / (1 + torch.exp(-(x_train.matmul(W) + b))) #시그모이드 함수
hypothesis = torch.sigmoid(x_train.matmul(W) + b) #위랑 같은 뜻인데 더 간단하게 연산
#cost function - 식으로 표현한 것
# losses = -(y_train * torch.log(hypothesis) + (1 - y_train) * torch.log(1 - hypothesis))
# cost = losses.mean()
F.binary_cross_entropy(hypothesis, y_train) #위의 두줄과 같은 뜻인데 더 간단하게!
#---------------------------------------------------------
#직접 돌려보자!
x_data = [[1, 2], [2, 3], [3, 1], [4, 3], [5, 3], [6, 2]]
y_data = [[0], [0], [0], [1], [1], [1]]
x_train = torch.FloatTensor(x_data)
y_train = torch.FloatTensor(y_data)
W = torch.zeros((2, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
# optimizer 설정 - sgd를 사용, 학습률은 1
optimizer = optim.SGD([W, b], lr=1)
nb_epochs = 1000
for epoch in range(nb_epochs + 1):
#시그모이드 계산(가설)
hypothesis = torch.sigmoid(x_train.matmul(W) + b)
# Cost 계산
cost = F.binary_cross_entropy(hypothesis, y_train)
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward() # 미분하기
# 구한 loss로부터 back propagation을 통해 각 변수마다 loss에 대한 gradient 를 구해주기
optimizer.step() #model의 파라미터들이 업데이트 됨
# 100번마다 로그 출력
if epoch % 100 == 0:
print('Epoch {:4d}/{} Cost: {:.6f}'.format(
epoch, nb_epochs, cost.item()
))
prediction = hypothesis >= torch.FloatTensor([0.5]) #임계값을 주고 0, 1로 구분
4. Full code with nn.Module
#import, data는 위와 동일
class BinaryClassifier(nn.Module): #class 만들어주기
def __init__(self):
super().__init__()
self.linear = nn.Linear(2, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
return self.sigmoid(self.linear(x)) #linear를 sigmoid태워줌
model = BinaryClassifier() #model생성
# optimizer 설정
optimizer = optim.SGD(model.parameters(), lr=1)
nb_epochs = 10000
for epoch in range(nb_epochs + 1):
# H(x) 계산
hypothesis = model(x_train)
# cost 계산
cost = F.binary_cross_entropy(hypothesis, y_train)
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
# 20번마다 로그 출력
if epoch % 100 == 0:
prediction = hypothesis >= torch.FloatTensor([0.5])
correct_prediction = prediction.float() == y_train
accuracy = correct_prediction.sum().item() / len(correct_prediction)
print('Epoch {:4d}/{} Cost: {:.6f} Accuracy {:2.2f}%'.format(
epoch, nb_epochs, cost.item(), accuracy * 100,
))
etc. regression, classification
regression은 회귀라고 하는데, 일반적으로 표현하자면 fitting이라고 할 수 있다.
즉, lienar regression이란 어떤 data의 분포가 linear하다고 가정하고, 이 linear 함수를 찾는 것이다.
1차 함수를 막대기로 표현 하지면 data의 분포를 가장 잘 나타낼 수 있는 막대기의 위치와 기울기를 찾는 것이다.
다르게 말하자면 data라 이 linear 함수를 따르기 때문에, 그러한 모양으로 분포되어 있다고도 할 수 있다.
즉, data의 분포를 이루는 함수의 원형을 찾아가는 것이 회귀라고 할 수 있다.
logstic regression은 데이터의 cost funtion을 최소화 하도록 logistic function을 regression하는 것을 의미한다.
보통 continuous 한 값에 대해서는 linear regression을 사용하고, 0 또는 1의 classification은 logistic regression을 사용한다.
classification은 0이냐 1이냐 값을 매기는 것입니다. 그렇기 때문에 logistic function을 이용한 regression이 더 적합하다.
<Reference>
https://deeplearningzerotoall.github.io/season2/lec_pytorch.html