06. softmax classification
본 글은 '모두를 위한 딥러닝 시즌 2'와 'pytorch로 시작하는 딥 러닝 입문'을 보며 공부한 내용을 정리한 글입니다.
필자의 의견이 섞여 들어가 부정확한 내용이 존재할 수 있습니다.
3개 이상의 선택지에서 1개를 선택! (soft하게 max값을 뽑아주는)
⇒ 다중 클래스 분류 (Multi-class classification)
세 개 이상의 답 중 하나를 고르는 문제.
시그모이드 함수는 로지스틱 함수의 한 케이스라 볼 수 있고, 인풋이 하나일 때 사용되는 시그모이드 함수를 인풋이 여러개일 때도 사용할 수 있도록 일반화 한 것이 소프트맥스 함수입니다.
0. 원-핫 인코딩(one-Hot Encoding)
- 선택지의 개수만큼 차원을 가진다.
- 선택지에 해당하는 인덱스는 1, 나머지는 0으로 표현한다.
ex)
강아지 = [1, 0, 0]
고양이 = [0, 1, 0]
냉장고 = [0, 0, 1]
-
정수 인코딩(1, 2, 3)과의 차이점
⇒ 정수 인코딩은 각 클래스가 순서 정보를 필요로 할 때 유용하다.
⇒ 원 핫 인코딩은 일반적인 분류문제, 즉 순서가 의미없고 무작위성이 있을 때 유용하다.
(모든 클래스의 관계를 균등하게 분배하기 때문!)
1. softmax function
각 선택지마다 소수를 할당해서 그 합이 1이 되게 만드는 함수.
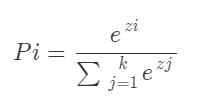
for i = 1, 2, ..., k
pi는 i번 클래스가 정답일 확률을 뜻한다. pi(i=1~k)를 다 더하면, 그 합은 1이 된다. 즉, 소프트 맥스 함수는 어렵게 생각할 필요 없이 주어진 값들에 대해 합이 1이 되도록 그 값들을 비율에 맞춰 소수로 정규화 시켜주는 함수라고 생각하면 된다.
Softmax( ( 1xf ) * ( fxC ) + ( Cx1 ) ) = C x 1
차례로 입력값, 가중치, 편향, 예측값이다. (f는 특성의 수, C는 클래스의 개수)
데이터의 개수에 따라서 입력값의 1이 바뀐다.
2. cost function
logistic regresstion에서는 binary cross-entropy를 사용했다. 얘는 2개 중 하나를 결과값으로 내 놓았었는데, 이 BCE 보다 더 근원적인? 함수가 있다. 바로 CE! cross entropy!
CE는 3개 이상의 값 중 하나를 내어 놓는다.
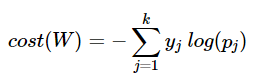
여기서 최대값인 K를 2로 지정하게 된다면, BCE의 식이 나오게 된다!
3. Code 구현
softmax와 cross-entropy의 구현 방법에는 3가지가 있다.
#1
F.softmax() + torch.log() # = F.log_softmax()
#2
F.log_softmax() + F.nll_loss() # = F.cross_entropy()
#3
F.cross_entropy()결론적으로는 편하게 3번만 사용하면 된다! 특이하게 가설 함수와 손실 함수를 한번에 쓸 수 있다! 이럴 경우, 실제 code에서는 행렬의 곱만 시켜주고, 소수 합이 1이 되도록 정규화 시켜주는 과정은 손실함수를 쓸 때 같이 할 수 있는 저 F.cross_entropy()에 맞겨주면 된다.
4. Full Code
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
x_train = [[1, 2, 1, 1], #4개의 특성을 가지고 있는 8개의 테스트 케이스
[2, 1, 3, 2],
[3, 1, 3, 4],
[4, 1, 5, 5],
[1, 7, 5, 5],
[1, 2, 5, 6],
[1, 6, 6, 6],
[1, 7, 7, 7]]
y_train = [2, 2, 2, 1, 1, 1, 0, 0]
x_train = torch.FloatTensor(x_train) #텐서로 변환
y_train = torch.LongTensor(y_train)
y_one_hot = torch.zeros(8, 3)
#앞의 8은 테스트 케이스 개수, 뒤의 3은 답이 2일때 [0 0 1] 이런식으로 나타낼 것(지금은 자리만 만듦)
y_one_hot.scatter_(1, y_train.unsqueeze(1), 1) #실제 값 y를 원-핫 벡터로 바꿈
print(y_one_hot.shape)
# 모델 초기화
W = torch.zeros((4, 3), requires_grad=True) #특성은 4개, 결과 가지수는 3개
b = torch.zeros(1, requires_grad=True) #1로 하면 3개에 같은 값이 더해짐, 3으로 해도 상관없음!
# optimizer 설정
optimizer = optim.SGD([W, b], lr=0.1)
nb_epochs = 1000
for epoch in range(nb_epochs + 1):
# 가설
hypothesis = F.softmax(x_train.matmul(W) + b, dim=1)
# 비용 함수 - 직접 계산 버전
cost = (y_one_hot * -torch.log(hypothesis)).sum(dim=1).mean()
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
# 100번마다 로그 출력
if epoch % 100 == 0:
print('Epoch {:4d}/{} Cost: {:.6f}'.format(
epoch, nb_epochs, cost.item()
))
4-1. Full Code with nn,Module
class SoftmaxClassifierModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(4, 3) # 인풋은 4, Output이 3!
def forward(self, x):
return self.linear(x)
model = SoftmaxClassifierModel() #모델 생성
# optimizer 설정
optimizer = optim.SGD(model.parameters(), lr=0.1)
nb_epochs = 1000
for epoch in range(nb_epochs + 1):
# H(x) 계산 - 행렬 곱만 해준다
prediction = model(x_train)
# cost 계산 - 이 함수서 softmax자동으로 적용됨
cost = F.cross_entropy(prediction, y_train)
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
# 20번마다 로그 출력
if epoch % 100 == 0:
print('Epoch {:4d}/{} Cost: {:.6f}'.format(
epoch, nb_epochs, cost.item()
))
<Reference>
https://deeplearningzerotoall.github.io/season2/lec_pytorch.html