-
본 글은 '모두를 위한 딥러닝 시즌 2'와 'pytorch로 시작하는 딥 러닝 입문'을 보며 공부한 내용을 정리한 글입니다.
필자의 의견이 섞여 들어가 부정확한 내용이 존재할 수 있습니다.
1. 학습률 (Learning late)
gradient descent를 할 때, 발자국의 크기를 정하는 일! 즉, 얼마나 이동할지 정한다.
처음에 한 0.1 정도에서 시작하다가 너무 발산하면 줄이고, 너무 진전이 없으면(변화가 없으면) 늘리는 식으로 최적의 학습률을 찾아가야 한다.
2. Data Preprocessing
데이터 전처리.
데이터의 크기 편차가 너무 크면, 큰 값에만 집중하게 되어서 학습이 잘 되지 않을 수 있다.
정규분포화(standardization)을 통해서 균등하게 만들어 줘야 한다.
mu = x_train.mean(dim=0) sigma = x_train.std(dim=0) norm_x_train = (x_train - mu) / sigma자매품으로 가중치 전처리도 있다. 09-2에 나온다.
3. MNIST
방대한 양의 손글씨 데이터를 모아놓은 데이터 Set!
1) torch vision
유명한 데이터 셋, 모델 아키텍쳐, 트랜스 폼 등등을 제공한다.
2) introduction
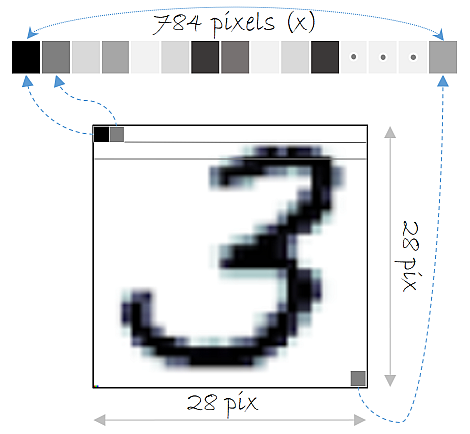
- 28 x 28 image => 784 (input의 개수)
- 1 channel gray image (색상이 흑백이다 = 1채널이다)
- 0~9 digits (0부터 9까지의 숫자가 있다, output의 개수)
3) Reading data
import torchvision.datasets as dsets ... mnist_train = dsets.MNIST(root="MNIST_data/", train=True, transform=transforms.ToTensor(), download=True) mnist_test = dsets.MNIST(root="MNIST_data/", train=False, transform=transforms.ToTensor(), download=True)dsets.MNIST
- root = mnist dataset이 있는(있을) 장소 - 파일 위치
- train = T면 학습 데이터, F면 테스트 데이터 사용
- transform = 데이터의 형태를 결정. ToTenser()를 하면 pytorch에서 쓰는 형태로 데이터를 바꿔줌.
- download = T면 파일 경로에 데이터 셋이 없을 경우, 다운로드를 받겠다고 명시.
data_loader = torch.utils.DataLoader(DataLoader=mnist_train, batch_size=batch_size, shuffle=True, drop_last=True)Data loader : mini batch를 만들 때 사용.
- DataLoader = 이 데이서 셋에서 데이터를 가져오겠다.
- batch_size = 얼마의 크기로 이들을 나눌 것이다.
- shuffle = 학습할 때 마다 데이터를 섞어 주겠다.
- drop_last = T라면, 마지막 배치가 딱 안떨어지고 애매하게 남을 때 그 배치를 버린다. (다른 미니 배치보다 개수가 적은 마지막 배치가 상대적으로 과대 평가되는 현상을 방지)
for epoch in range(training_epochs): ... for x, y in data_loader: X = X.view(-1, 28*28).to(device)x에는 mnist image, y에는 label(0~9)이 들어감.
view를 이용해서 데이터 형식을 바꿔준다. (B, 1, 28, 28) -> (B, 784)
4) etc...
- Epoch : 가지고 있는 데이터 셋 전체가 트레이닝에 모두 사용이 된다 => 한 에폭을 돌았다.
- batch size : 전체 데이터를 얼마의 크기로 자르느냐.
- Iteration : 전체 데이터를 배치 사이즈만큼 나누면 나오는 덩어리의 개수. 그 개수의 Iteration을 돌았다 -> 1 epoch
5) softmax train
import torch import torchvision.datasets as dsets import torchvision.transforms as transforms import matplotlib.pyplot as plt import random device = 'cuda' if torch.cuda.is_available() else 'cpu' # for reproducibility random.seed(777) torch.manual_seed(777) if device == 'cuda': torch.cuda.manual_seed_all(777) # hyperparameters training_epochs = 15 batch_size = 100 # MNIST dataset mnist_train = dsets.MNIST(root='MNIST_data/', train=True, transform=transforms.ToTensor(), download=True) mnist_test = dsets.MNIST(root='MNIST_data/', train=False, transform=transforms.ToTensor(), download=True) data_loader = torch.utils.data.DataLoader(dataset=mnist_train, batch_size=batch_size, shuffle=True, drop_last=True) # MNIST data image of shape 28 * 28 = 784 (input), output => 0~9 (10개) linear = torch.nn.Linear(784, 10, bias=True).to(device) # to() = 연산을 어디서 수행할지 정함.(기본은 CPU) #bias - 편향을 사용할건지 (기본값은 T) # define cost/loss & optimizer criterion = torch.nn.CrossEntropyLoss().to(device) # Softmax is internally computed. optimizer = torch.optim.SGD(linear.parameters(), lr=0.1) for epoch in range(training_epochs): # 앞서 training_epochs의 값은 15로 지정함. avg_cost = 0 total_batch = len(data_loader) for X, Y in data_loader: #Iteration 돌려주기 (이게 다 돌면 1epoch) # 배치 크기가 100이므로 아래의 연산에서 X는 (100, 784)의 텐서가 된다. X = X.view(-1, 28 * 28).to(device) # 레이블은 원-핫 인코딩이 된 상태가 아니라 0 ~ 9의 정수. Y = Y.to(device) optimizer.zero_grad() hypothesis = linear(X) cost = criterion(hypothesis, Y) cost.backward() optimizer.step() avg_cost += cost / total_batch print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.9f}'.format(avg_cost)) print('Learning finished') # Test the model using test sets with torch.no_grad(): X_test = mnist_test.test_data.view(-1, 28 * 28).float().to(device) Y_test = mnist_test.test_labels.to(device) prediction = linear(X_test) correct_prediction = torch.argmax(prediction, 1) == Y_test accuracy = correct_prediction.float().mean() print('Accuracy:', accuracy.item()) # Get one and predict r = random.randint(0, len(mnist_test) - 1) X_single_data = mnist_test.test_data[r:r + 1].view(-1, 28 * 28).float().to(device) Y_single_data = mnist_test.test_labels[r:r + 1].to(device) print('Label: ', Y_single_data.item()) single_prediction = linear(X_single_data) print('Prediction: ', torch.argmax(single_prediction, 1).item()) plt.imshow(mnist_test.test_data[r:r + 1].view(28, 28), cmap='Greys', interpolation='nearest') plt.show()
<Reference>
https://deeplearningzerotoall.github.io/season2/lec_pytorch.html
'📚STUDY > 🔥Pytorch ML&DL' 카테고리의 다른 글
09-1. 활성화 함수(Activation function) (0) 2020.03.07 08. Perceptron (0) 2020.03.03 06. softmax classification (0) 2020.02.28 05. Logistic Regression (0) 2020.02.28 04-2. Loading Data(Mini batch and data load) (0) 2020.02.24 댓글
💾
AtoZ; 처음부터 끝까지 기록하려고 노력합니다✍
